
이전 시간에 원-핫 벡터는 단어 벡터 간 유의미한 유사도를 계산할 수 없는 단점이 있습니다.
이 유사도를 반영해서 수치화할 수 있는 방법인 Word2Vec가 등장하게 됩니다.
1. 워드 투 벡터란
기존의 원-핫 벡터는 단어 집합의 크기가 차원입니다.
단어 집합 {hello, nice, to, meet, you}

이 방법은 표현할 단어만 1이고 나머지는 0으로 표현되기 때문에 희소 표현(sparse representation)이라고 합니다.
하지만, 이는 단어의 유사성을 표현할 수 없고 대부분의 단어가 0으로 표현되기 때문에 매우 비효율적입니다.
이에 분산 표현(Distributed Representation)이 등장하게 됩니다.
이 분산 표현은 '비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다'라는 가정을 해야합니다.
분산 표현은 분산 가설을 이용하여 텍스트를 학습하고 단어의 의미를 여러 차원에 '분산'하여 표현합니다.
위에서 표현된 단어 집합 {hello, nice, to, meet, you} 로 예시를 들겠습니다.
비슷한 문맥에서 등장하는 단어는 비슷한 의미를 가지는 가정을 했기 때문에
nice 라는 단어를 확인하면
ex)

nice 를 분산 표현을 통해 학습을 하니까 수치들이 여러 차원에 분산되어 표시됩니다.
이 수치를 보면 nice 와 유사도가 가까운 단어가 표시되는 것입니다.
| 단어집합 -> | hello | nice | to | meet | you |
| nice | 0.9 | 0.8 | 0.5 | 0.6 | 0.7 |
이 분산표현을 통해 학습한 nice는 hello, nice, you, meet, to 순으로 유사도가 높게 나온다는 것입니다.
( 수치는 예시입니다)
이 방식의 대표적인 학습 방법이 Word2Vec입니다.
이 Word2Vec 에는 2가지 방식이 있습니다.
2. CBOW(Continous Bag Of Words)
CBOW는 주변에 있는 단어들을 입력으로 중간에 있는 단어를 예측하는 방식입니다.
예문 : " The fat cat sat on the mat"
이 예문에서 sat라는 단어를 The fat cat on the mat 으로부터 예측해보겠습니다.
이때 예측해야하는 단어 sat을 중심단어(Center word)라고 하고
예측에 사용되는 단어를 주변 단어(Context word)라고 합니다.
중심단어를 예측하기 위해 앞 뒤로 몇개의 단어를 볼지 정해야 하는데 이 범위를 윈도우(window)라고 합니다.
window = 2 라고 가정할 경우 중심단어 sat에서 앞의 두 단어 fat cat과 뒤의 두 단어 on the를 입력으로 사용하게 됩니다.
이를 도식화하면 다음과 같습니다.

다음으로 윈도우를 옆으로 움직여 주변 단어와 중심 단어를 바꿔가며 학습하는 단계를 슬라이딩 윈도우라고 합니다.

3. Skip-gram
CBOW가 주변단어를 통해 중심단어를 예측한다면 Skip-gram은 반대입니다.
Skip-gram은 중심단어를 통해 주변단어를 예측합니다.
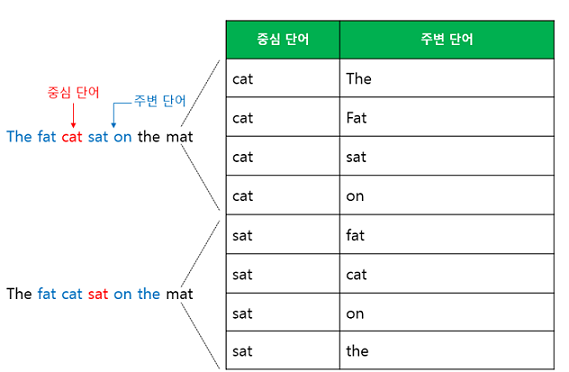
이를 도식화하면 다음과 같습니다.

4. 한계점
Word2Vec에도 한계점이 있습니다.
1. 단어의 형태학적 특성을 반영하지 못한다.
teach, teacher, teaches 이 세 단어는 의미적으로 유사한 단어입니다.
하지만, 각 단어를 개별로 처리하기 때문에 벡터 값이 다르게 구성됩니다.
2. 단어 빈도 수의 영향을 많이 받아 희소한 단어를 임베딩하기 어렵다.
단어 빈도수의 영향을 많이 받기 때문에 희소한 단어를 임베딩하기 어렵습니다.
3. OOV(Out of Vocabulary)의 처리가 어렵다.
OOV는 사전에 없는 단어를 의미합니다.
단어 단위로 학습하는 Word2Vec의 특성 상
새로운 단어가 등장하면 데이터 전체를 학습시켜야 합니다.
CBOW와 Skip-gram의 부족한 메커니즘 설명 부분은 다음 자료를 참고해주세요.
참고자료 : https://wikidocs.net/22660
09-02 워드투벡터(Word2Vec)
앞서 원-핫 벡터는 단어 벡터 간 유의미한 유사도를 계산할 수 없다는 단점이 있음을 언급한 적이 있습니다. 그래서 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를…
wikidocs.net
'NLP' 카테고리의 다른 글
| [NLP]원-핫 인코딩(One-Hot Encoding) (0) | 2024.04.12 |
|---|